🚀 Primary vs Replica | Quản lý và Tối ưu hóa Dữ liệu trong Hệ thống phân tán
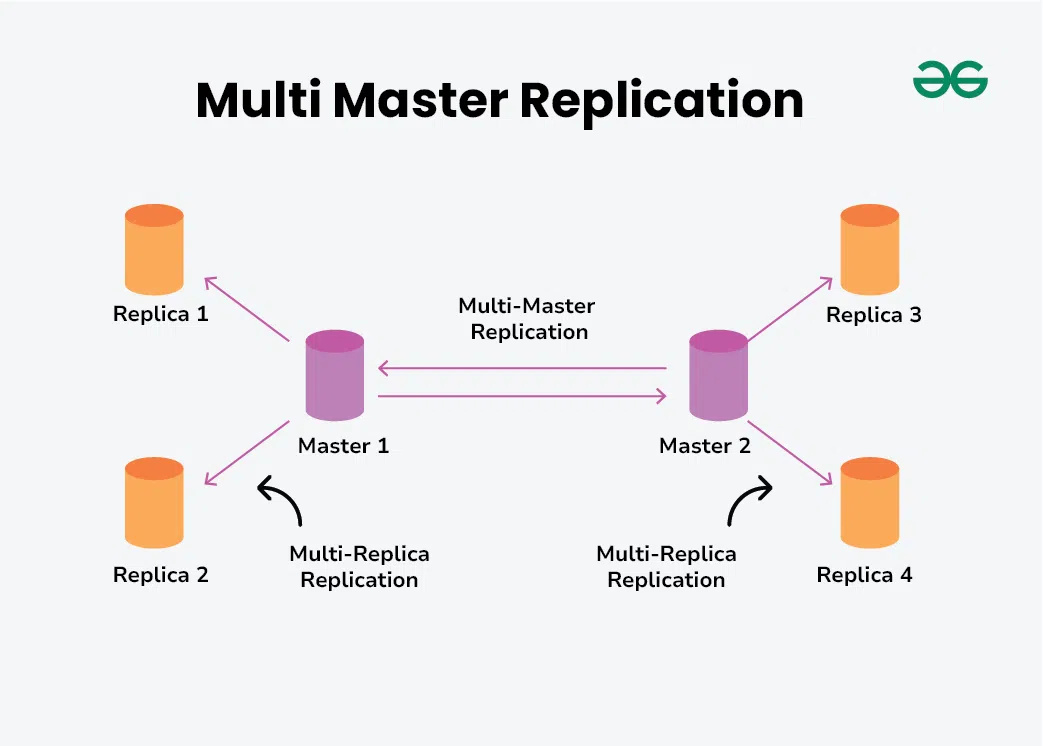
🎯 Giới thiệu về Primary và Replica
Trong các hệ thống phân tán và quản lý cơ sở dữ liệu, thuật ngữ Primary và Replica đề cập đến một mô hình phân phối dữ liệu, giúp tăng tính khả dụng, mở rộng và tối ưu hóa hiệu suất. Cấu trúc Primary - Replica được áp dụng phổ biến trong các cơ sở dữ liệu, hệ thống container và môi trường đám mây để quản lý các bản sao dữ liệu và đảm bảo rằng dịch vụ luôn sẵn sàng và hoạt động hiệu quả.
✅ Primary Node (Chính)
- Primary Node là node chính, chịu trách nhiệm thực hiện các thay đổi đối với dữ liệu trong hệ thống. Tất cả các yêu cầu ghi (insert, update, delete) đều được thực hiện trên Primary Node.
- Primary Node đóng vai trò quản lý và điều phối dữ liệu, thường đảm bảo tính nhất quán của dữ liệu trong hệ thống.
✅ Replica Node (Sao chép)
- Replica Node là các bản sao của Primary Node. Các Replica chỉ giữ dữ liệu đọc và không thực hiện bất kỳ thay đổi nào đối với dữ liệu.
- Replica Nodes giúp giảm tải cho Primary Node và cung cấp tính khả dụng cao. Nếu Primary Node gặp sự cố, một trong các Replica có thể được chuyển thành Primary để đảm bảo không gián đoạn dịch vụ.
🛠️ Cách thức hoạt động của Primary và Replica
✅ Quy trình đồng bộ hóa
Khi một thay đổi được thực hiện trên Primary Node, dữ liệu sẽ được replicated (sao chép) đến các Replica Nodes. Điều này đảm bảo rằng tất cả các Replica luôn đồng bộ với Primary và có dữ liệu mới nhất.
- Primary Node nhận các yêu cầu ghi và thực hiện thay đổi dữ liệu.
- Sau khi thay đổi được thực hiện, Replica Nodes sẽ nhận bản sao của dữ liệu từ Primary thông qua cơ chế đồng bộ hóa.
- Replica Nodes chỉ thực hiện yêu cầu đọc dữ liệu, giúp giảm tải cho Primary Node và cung cấp sự mở rộng.
✅ Quản lý sự cố và chuyển đổi
Trong trường hợp Primary Node gặp sự cố hoặc không hoạt động, một Replica Node có thể được nâng cấp lên làm Primary để duy trì hoạt động liên tục. Quá trình này giúp hệ thống luôn có một bản sao dữ liệu sẵn sàng mà không gặp gián đoạn.
🧑💻 Lợi ích của mô hình Primary - Replica
1️⃣ Tính khả dụng cao
- Khi Primary Node gặp sự cố, một trong các Replica Nodes có thể được chuyển thành Primary để tiếp tục cung cấp dịch vụ, giảm thiểu thời gian gián đoạn.
2️⃣ Tăng hiệu suất
- Các Replica Nodes phục vụ các yêu cầu đọc, giúp giảm tải cho Primary Node. Điều này giúp tăng hiệu suất của hệ thống và xử lý các yêu cầu đồng thời tốt hơn.
3️⃣ Dự phòng dữ liệu
- Replica là bản sao của Primary, giúp dữ liệu luôn được sao lưu và bảo vệ. Nếu có sự cố xảy ra với Primary, bạn có thể phục hồi dữ liệu từ các Replica Nodes.
4️⃣ Cân bằng tải (Load Balancing)
- Replica Nodes có thể được sử dụng để phân phối tải đọc từ các người dùng hoặc ứng dụng, giúp tối ưu hóa hiệu suất và giảm tải cho Primary Node.
✅ Nhược điểm của mô hình Primary - Replica
1️⃣ Chi phí triển khai
- Việc duy trì Replica Nodes có thể tốn kém, đặc biệt đối với các hệ thống lớn với nhiều Primary và Replica. Ngoài chi phí phần cứng, bạn cũng phải chi trả cho chi phí mạng và lưu trữ.
2️⃣ Độ trễ trong sao chép dữ liệu
- Do sự đồng bộ hóa giữa Primary và Replica có thể gặp độ trễ, Replica không phải lúc nào cũng có dữ liệu mới nhất ngay lập tức. Điều này có thể gây ra việc Replica không có dữ liệu mới nhất ngay lập tức.
3️⃣ Khó khăn trong việc quản lý
- Việc quản lý các Primary và Replica Nodes có thể trở nên phức tạp khi số lượng các node tăng lên, đặc biệt khi cần đồng bộ hóa dữ liệu và xử lý các sự cố.
🧑💻 Khi nào nên sử dụng mô hình Primary - Replica?
✅ 1. Hệ thống yêu cầu tính khả dụng cao
- Khi bạn cần bảo đảm hệ thống luôn sẵn sàng và không gặp gián đoạn, mô hình Primary - Replica là lựa chọn lý tưởng, đặc biệt trong các hệ thống tài chính, ngân hàng, dịch vụ trực tuyến.
✅ 2. Các ứng dụng cần xử lý nhiều yêu cầu đọc
- Nếu hệ thống của bạn cần xử lý một lượng lớn yêu cầu đọc và không cần thay đổi dữ liệu thường xuyên, sử dụng Replica Nodes để giảm tải cho Primary Node sẽ giúp tối ưu hóa hiệu suất.
✅ 3. Các ứng dụng đám mây và hệ thống phân tán
- Mô hình Primary - Replica là một phần quan trọng trong các ứng dụng đám mây và hệ thống phân tán, giúp cung cấp sự mở rộng và dự phòng dữ liệu mà không làm giảm hiệu suất.
✅ 4. Dự phòng và sao lưu dữ liệu
- Nếu bạn cần sao lưu dữ liệu và phục hồi nhanh chóng, Replica Nodes sẽ giúp bạn đảm bảo rằng dữ liệu luôn có bản sao và có thể khôi phục trong trường hợp có sự cố.
🧑💻 Ví dụ về Primary - Replica
✅ 1. Cơ sở dữ liệu MySQL
Trong MySQL, bạn có thể cấu hình Primary - Replica để sao chép dữ liệu giữa các server. Primary sẽ xử lý các thao tác ghi, còn các Replica chỉ phục vụ yêu cầu đọc, giúp giảm tải cho Primary. Ví dụ, trong môi trường có lượng truy cập lớn, các Replica sẽ chịu trách nhiệm xử lý các yêu cầu truy vấn dữ liệu mà không làm giảm hiệu suất của Primary Node.
- Primary Node:
192.168.1.10 - Replica Node:
192.168.1.20
Khi có thay đổi dữ liệu trên Primary, nó sẽ tự động được sao chép vào Replica để đảm bảo tính đồng bộ dữ liệu.
✅ 2. Các dịch vụ Web và API
Trong các ứng dụng web hoặc API yêu cầu khả năng chịu tải lớn, mô hình Primary - Replica cũng có thể được sử dụng. Primary Node xử lý các yêu cầu viết (POST, PUT, DELETE), trong khi các Replica Nodes sẽ phục vụ các yêu cầu đọc (GET) để giảm tải cho Primary.
Ví dụ: Một API chia sẻ dữ liệu mà trong đó các yêu cầu đọc (GET) có thể được xử lý bởi Replica nodes để đảm bảo hiệu suất cao và đáp ứng nhanh chóng cho người dùng.
🚀 Tổng kết
Mô hình Primary - Replica là một giải pháp quan trọng trong việc quản lý dữ liệu và đảm bảo tính khả dụng cao cho hệ thống. Bằng cách phân chia các tác vụ đọc và ghi giữa Primary Node và Replica Nodes, bạn có thể tối ưu hóa hiệu suất và giảm thiểu rủi ro gián đoạn dịch vụ. Tuy nhiên, cũng cần phải cân nhắc các chi phí triển khai và độ phức tạp trong việc quản lý các node trong cluster.